Machine Learning¶
Basic Concepts¶
Hyperplane: \(\lbrace \mathbf{x} : \mathbf{w}^T\mathbf{x}=b \rbrace\), \(\mathbf{w,x}\in \mathbb{R}^d\), \(b\in \mathbb{R}\). A set of points in \(\mathbb{R}^d\) with a constant inner product to a given vector \(\textbf{w} \in \mathbb{R}^d\). The constant \(b\) determines the offset of the hyperplane \((\textbf{w},b)\) from the origin.
Training Set \(T\) : The set of pairs \((\mathbf{x}_t , y_t ) \subset \mathbb{R}^d \times \mathbb{R}\) where the vectors \(\mathbf{x}_t\) are samples with known behaviour and \(y_t\) are their labels. In classification, for each sample \(\mathbf{x}_t\) in the training set, a label \(y_t\) is assigned which classifies the sample in one of any given number of classes. In the notation \(\mathbf{x}_t\), \(t\) belongs to the set \(\lbrace 1, 2, ..., l \rbrace\) where \(l\) is the total number of samples in the training set.
Output Domain \(Y\) : For binary classification of the vectors in \(T\), the output domain is \(Y=\lbrace -1, 1 \rbrace\). A classifier function is developed based on the training set which assigns any new d-dimensional vector to one of the classes -1 and 1 correctly. In the ideal case the samples in the training set describe the general behavour of the vectors in the class sufficiently well so that the classifier function is able to classify any vector correctly, otherwise the classifier needs to be updated using new training samples.
Linear Binary Classification¶
Classification function: The classification function is defined as
In Eq. (1) \(\mathbf{w}\) is the weight vector having the same dimension as the training sample vectors \(\mathbf{x}_t\) and \(b\) is the bias coefficient. The symbol \(\langle\cdot,\cdot\rangle\) denotes the scalar product of two vectors.
The classifier function can be obtained using the perceptron algorithm.
The Perceptron Algorithm: A supervised learnign algorithm based on the gradual improvement of a classifier function until it classifies all the samples in the taining set correctly. The steps of the algorithm can be summarized as follows:
- Initialize: \(\mathbf{w}^{(0)}=\mathbf{0}\), \(b^{(0)}=0\), total number of updates=0, number of misclassifications in one pass=0, \(R=\max \Vert\mathbf{x}_t\Vert\)
- for t=1 to number of samples: Check if \(y_t(\langle \mathbf{w}^{(k)}, \mathbf{x}_t \rangle + b^{(k)} )>0\) is satisfied.
- If the above condition is not satisfied then do:
- \(\mathbf{w}^{(k+1)}=\mathbf{w}^{(k)}+y_t\mathbf{x}_t\)
- \(b^{(k+1)}=b^{(k)}+y_tR^2\)
The perceptron algorithm uses a training set \(T=\lbrace(\mathbf{x}_t,y_t):\mathbf{x}_t\in\mathbb{R}^d, y_t\in\lbrace-1,1\rbrace\rbrace\) of samples with known behaviour in order to obtain a proper weight vector and bias coefficient. The letter \(t\) in the notation for a training sample \(\mathbf{x}_t\) is the index of the training sample and belongs to the set \(\lbrace 1,...,l\rbrace\) where \(l\) is the total number of training samples. For each training sample \(\mathbf{x}_t\) in the training set, a label \(y_t\) is assigned according to the known behaviour of the sample.
The classifier function in Eq. (1) makes a decision about the class of a vector \(\mathbf{x}_t\) which depends on the expression \(\langle \mathbf{w}, \mathbf{x}_t\rangle+b\) having a value greater than 0 or not. Therefore the set of vectors \(\mathbf{x}\) in the \(\mathbb{R}^d\) space for which this expression is equal to 0 builds the decision boundary of the training set.
Formally the decision boundary is defined as \(DB =\lbrace \mathbf{x}\in\mathbb{R}^d:\langle\mathbf{w},\mathbf{x}\rangle+b = 0\rbrace\).The weight vector \(\mathbf{w}\) determines the orientation of the decision boundary and is perpendicular to it. In order to show this, let \(\mathbf{v}_1\) and \(\mathbf{v}_2\) be any two vectors in \(DB\). Then \(\langle\mathbf{w},\mathbf{v}_1\rangle+b=\langle\mathbf{w},\mathbf{v}_2\rangle+b=0\) and \(\langle\mathbf{w},\mathbf{v}_1-\mathbf{v}_2\rangle=0\). Therefore any vector lying within \(DB\) is perpendicular to \(\mathbf{w}\). This can be easily visualized in \(\mathbb{R}^2\).
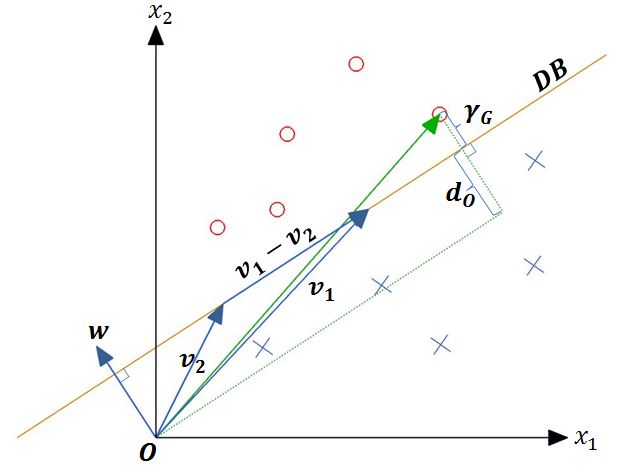
In the above figure, the symbols ‘x’ and ‘o’ represent the samples of two different classes and \(\gamma_G\) denotes the geometric margin of the decision boundary \(DB\) between these two classes. The geometric margin is the smallest distance between any sample in the training set and the hyperplane that separates the two classes in the training set (the decision boundary). An expression to compute the magnitude of the geometric margin can be obtained as follow: Let \(\mathbf{x}_t\) be the training sample having the least distance to the decision boundary. Then, \(\mathbf{x}_t\) can be expressed as the sum of its orthogonal projection on \(DB ((\mathbf{x}t)_\bot)\) and another vector which is parallel to the weight vector \(\mathbf{w}\) as in Eq. (2)
In Eq. (2), \(d_O\) is the distance of the decision boundary from the origin and is closely related to the bias coefficient b first introduced in Eq. (1). In order to see that, let \(\mathbf{x}_0\) be a vector that is perpendicular to the decision boundary and has a magnitude equal to the distance of the decision boundary from the origin such that \(\Vert \mathbf{x}_0 \Vert = d_O\). then \(\mathbf{x}_0\) has the same direction as \(\mathbf{w}\) and can be written as \(\mathbf{x}_0=\Vert\mathbf{x}_0\Vert\displaystyle\frac{\mathbf{w}}{\Vert\mathbf{w}\Vert}\). Clearly, \(\mathbf{x}_0\) is also in the decision boundary and therefore \(\langle\mathbf{w},\mathbf{x}_0\rangle+b=\displaystyle\frac{\Vert\mathbf{x}_0\Vert}{\Vert\mathbf{w}\Vert}\langle \mathbf{w},\mathbf{w} \rangle + b=\Vert\mathbf{x}_0\Vert\Vert\mathbf{w}\Vert + b=0\). Therefore \(d_O\) can be computed as in Eq. (3).
Plugging the expression for \(d_O\) from Eq. (3) into Eq. (2) and taking the scalar product of both sides of the equation with \(\mathbf{w}\) we obtain Eq. (4)
Since \(\mathbf{w}\) and \((\mathbf{x}_t)_{\bot}\) are perpendicular to each other, the \(\langle\mathbf{w},(\mathbf{x}_t)_{\bot}\rangle\) term in Eq. (4) vanishes. After adding \(b\) to both sides of Eq. (4), we obtain Eq. (5) which shows the expression for the geometric margin \(\gamma_G\) [3].
The perceptron algorithm starts with the initialization of \(\mathbf{w}\) and \(b\) as \(\mathbf{w}^{(0)} = \mathbf{0}\), \(b^{(0)} = 0\). In the next step the algorithm traverses the training set. For each pipe sample \(\mathbf{x}_t\) in the training set, if the product y_t(langlemathbf{w}^{(k)}, mathbf{x}_trangle+b^{(k)}) is less than or equal to zero, then this would imply that the actual label of the training sample and the predicted label have opposite signs and the training sample is misclassified. In this case, \(\mathbf{w}^{(k)}\) and \(b^{(k)}\) are updated as follows:
where \(R=\max\Vert\mathbf{x}_t\Vert\). It can be proven that the above updates improve the weight vector and the bias coefficient as follows [1]: Assume that after the updates, another attempt is made in order to classify the same training sample \(\mathbf{x}_t\). Then Eq. (8) shows that the new product \(y_t(\langle \mathbf{w}^{(k+1)},\mathbf{x}_t\rangle+b^{(k+1)})\) is closer to a positive value compared to \(y_t(\langle \mathbf{w}^{(k)}, \mathbf{x}_t\rangle + b^{(k)})\).
It can also be proven that after a finite number of updates a proper classifier function can be obtained as long as the samples in the training set are linearly separable with a functional margin \(\gamma_F > 0\). The functional margin \(\gamma_t\) of a training sample \(\mathbf{x}_t\) with respect to a separating hyperplane (decision boundary) \((\mathbf{w}, b)\) is defined as [2]:
and the functional margin \(\gamma_F\) of a separating hyperplane \((\mathbf{w},b)\) is defined as the minimum of all functional margins associated with a training set. A larger functinal margin implies that the training samples are geometrically farther away from the separating hyperplane and therefore the two classes are more distinctly separated. The relationship between the functional margin and the geometric separateness of the classes can be reckoned by comparing the expressions for the geometric margin (Eq. (5)) and the functional margin (Eq. (9)).
In order to prove that the perceptron algorithm converges to a solution after a finite number of iterations, the following new weight vectors \(\mathbf{\widetilde{w}}\) and training samples \(\mathbf{\widetilde{x}}_t\) are defined by appending \(R\) to every training sample and \(b^{(k)}/R\) to every weight vector \(\mathbf{w}^{(k)}\):
Given that the training samples are linearly separable, there exists a separating hyperplane \(( \mathbf{w}^{*},b^{*} )\) such that for any \((\mathbf{x}_t,y_t) \in T\), \(y_t(\langle \mathbf{w}^{*},\mathbf{x}_t\rangle+b^{*})=y_t\langle\widetilde{\mathbf{w}}^{*},\widetilde{\mathbf{x}}_t\rangle\geq \gamma^{*}\) where \(\gamma^{*}\) is the functional margin of \(( \mathbf{w}^{*},b^{*})\).
Assume that the weight vector \(\widetilde{\mathbf{w}}^{(k-1)}\) resulted in a misclassification of the sample \(\widetilde{\mathbf{x}}_t\) and is therefore updated to \(\widetilde{\mathbf{w}}^{(k)}\). \(\widetilde{\mathbf{w}}^{(k)}\) and \(\widetilde{\mathbf{w}}^{*}\) both belong to the vector space \(\mathbb{R}^3\) and the cosine of the angle between them is defined as in Eq. (11).
In Eq. (11), the expression for \(\widetilde{\mathbf{w}}^{(k)}\) can be expanded as follows.
It can also be shown that the scalar product term in Eq. (11) is greater than or equal to \(k\gamma^*\). In order to show this let \(k=1\), then \(\langle \widetilde{\mathbf{w}}^*, \widetilde{\mathbf{w}}^{(1)} \rangle=\langle \widetilde{\mathbf{w}}^*, \widetilde{\mathbf{w}}^{(0)}+y_t\widetilde{\mathbf{x}}_t \rangle=y_t\langle \widetilde{\mathbf{w}}^*,\widetilde{\mathbf{x}}_t \rangle\geq \gamma^*\) since \(\widetilde{\mathbf{w}}^{(0)}\) is initialized as the zero vector. If for some \(n\in\mathbb{N}\), \(\langle\widetilde{\mathbf{w}}^*,\widetilde{\mathbf{w}}^{(n)}\rangle\geq n\gamma^*\), then \(\langle \widetilde{\mathbf{w}}^{*} , \widetilde{\mathbf{w}}^{(n+1)} \rangle=\langle \widetilde{\mathbf{w}}^*, \widetilde{\mathbf{w}}^{(n)}+y_t\widetilde{\mathbf{x}}_t \rangle=y_t\langle \widetilde{\mathbf{w}}^*, \widetilde{\mathbf{x}}_t \rangle + \langle \widetilde{\mathbf{w}}^*, \widetilde{\mathbf{w}}^{(n)} \rangle\geq\gamma^*+n\gamma^*=(n+1)\gamma^*\). By induction it follows that for any \(k\in\mathbb{N}\), \(\langle\widetilde{\mathbf{w}}^*, \widetilde{\mathbf{w}}^{(k)}\rangle\geq k\gamma^*\). Using this result the inequality in Eq. (12) is established.
Furthermore, the boundedness of the norm \(\Vert \widetilde{\mathbf{w}}^{(k)}\Vert\) can be shown as follows:
Since the weight vector \(\widetilde{\mathbf{w}}^{(k-1)}\) resulted in a misclassification, it is known that \(y_t\langle \widetilde{\mathbf{w}}^{(k-1)},\widetilde{\mathbf{x}}_t \rangle\leq 0\). Therefore,
Using \(\Vert \widetilde{\mathbf{x}}_t \Vert^2=\Vert\mathbf{x}_t\Vert^2+R^2\) yields
Eq. (13) implies the boundedness of \(\Vert\widetilde{\mathbf{w}}^{(k)}\Vert\). In order to prove this, consider that for \(k=1\), \(\Vert \widetilde{\mathbf{w}}^{(1)} \Vert^2\leq\Vert \widetilde{\mathbf{w}}^{(0)} \Vert^2+2R^2=2R^2=2kR^2\). If for some \(n\in \mathbb{N}\), \(\Vert\widetilde{\mathbf{w}}^{(n)}\Vert^2\leq 2 n R^2\) then using Eq. (13) we obtain \(\Vert\widetilde{\mathbf{w}}^{(n+1)}\Vert^2\leq\Vert\widetilde{\mathbf{w}}^{(n)}\Vert^2+2R^2\leq 2nR^2+2R^2=(n+1)2R^2\). By induction it follows that:
By plugging Eq. (14) in Eq. (12), squaring both sides of the inequality and using the boundedness of \(\widetilde{\mathbf{w}}^*\), Eq. (15) shows that only a finite number of iterations are needed in order to obtain a proper classifier function.
References
Tommi Jaakkola, course materials for 6.867 Machine Learning, Fall 2006. MIT OpenCourseWare (http://ocw.mit.edu/), Massachusetts Institute of Technology. Downloaded on [26 May 2014].
Cristianini N., Shawe-Taylor John: An Introduction to Support Vector Machines and other Kernel Based Learning Methods, Cambridge University Press 2000
Bishop C.M. (2006); “Pattern Recognition and Machine Learning”, Springer; 1st ed., ISBN-10: 0-387-31073-8